
İster kötü tavsiyeler üreten ChatGPT, sürücüsüz arabalar, yapay zeka kullanmakla suçlanan sanatçılar, yapay zekadan tıbbi tavsiye ve daha fazlası olsun, yapay zeka ve derin öğrenme bu günlerde sürekli olarak manşetlerde yer alıyor. Bu araçların çoğu, eğitim için çok sayıda donanıma sahip karmaşık sunuculara güvenir, ancak eğitimli ağı çıkarım yoluyla kullanmak, grafik kartı kullanılarak PC’nizde yapılabilir. Ancak yapay zeka çıkarımı yapmak için tüketici GPU’ları ne kadar hızlı?
Popüler bir yapay zeka görüntü yaratıcısı olan Stable Diffusion’ı en yeni Nvidia, AMD ve hatta Intel GPU’larla kıyaslayarak nasıl biriktiklerini gördük. Şans eseri, Stable Diffusion’ı kendi bilgisayarınızda çalışır duruma getirmeye çalıştıysanız, ne kadar karmaşık veya basit olduğuna dair bir fikriniz olabilir! – Bu olabilir. Kısa özet, Nvidia’nın GPU’larının, CUDA ve diğer Nvidia araç setleri kullanılarak tasarlanan çoğu yazılımla, tünekleri yönetmesidir. Ancak bu, Stable Difusion’ı diğer GPU’larda çalıştıramayacağınız anlamına gelmez.
Testimiz için üç farklı Stable Diffusion projesi kullandık, çünkü çoğunlukla her GPU’da tek bir paket çalışmıyordu. Nvidia için seçtik Otomatik 1111’in webui versiyonu (yeni sekmede açılır). AMD GPU’lar kullanılarak test edildi Nod.ai’nin Shark versiyonu (yeni sekmede açılır)Intel’in Arc GPU’ları için ise kullandık Kararlı Difüzyon OpenVINO (yeni sekmede açılır). Feragatnameler sırayla. Bu araçların hiçbirini kodlamadık, ancak çalıştırması kolay (Windows altında) ve aynı zamanda makul ölçüde optimize edilmiş gibi görünen şeyler aradık.
Nvidia 30 serisi testlerinin, özellikle performansta ~%20 ek bir artış sağlayan xformers etkinleştirildiğinde, optimum performansa yakın bir performans elde etme konusunda iyi bir iş çıkardığından nispeten eminiz. Bu arada RTX 40 serisi sonuçları, belki de yeni Ada Lovelace mimarisi için optimizasyon eksikliğinden dolayı beklenenden biraz daha düşük.
AMD sonuçları da biraz karışık, ancak Nvidia durumunun tersi: RDNA 2 GPU’lar oldukça vasat görünürken RDNA 3 GPU’lar oldukça iyi performans gösteriyor. Son olarak, Intel GPU’larda, nihai performans AMD seçenekleriyle düzgün bir şekilde aynı hizada görünse de, pratikte işleme süresi önemli ölçüde daha uzundur – muhtemelen onu yavaşlatan birçok ekstra arka plan olayı oluyor.
Ayrıca daha yeni SD 2.0 veya 2.1 yerine Stable Diffusion 1.4 modellerini kullanıyoruz, çünkü çoğunlukla SD2.1’i Nvidia olmayan bir donanımda çalıştırmak çok daha fazla çalışma gerektirecekti (ör. desteği etkinleştirmek için kod yazmayı öğrenmek). Ancak, Stable Diffusion hakkında biraz bilginiz varsa ve bizim kullandığımızdan daha iyi çalışabilecek farklı açık kaynak projeleri önermek istiyorsanız, yorumlarda bize bildirin (veya Jarred’e e-posta gönderin) (yeni sekmede açılır)).
resim 1 ile ilgili 11

Test parametrelerimiz tüm GPU’lar için aynıdır, ancak Intel sürümünde olumsuz bir komut istemi seçeneği yoktur (en azından, bulabildiğimizden değil). Yukarıdaki galeri, daha yüksek çözünürlüklü çıktılara sahip (çok, fazla tamamlanması daha uzun). Aynı istemler, ancak kıyaslamalarımız için kullandığımız 512×512 yerine 2048×1152’yi hedefliyoruz. İlgili ayarlar şunlardır:
Olumlu Bilgi İstemi:
kıyamet sonrası steampunk şehri, keşif, sinematik, gerçekçi, aşırı ayrıntılı, fotogerçekçi maksimum ayrıntı, hacimsel ışık, (((odak))), geniş açı, (((parlak ışıklı))), (((bitki örtüsü))), yıldırım sarmaşıklar, yıkım, yıkım, wartorn, kalıntılar
Negatif Bilgi İstemi:
(((bulanık))), ((sisli)), (((karanlık))), ((tek renkli)) güneş, (((alan derinliği)))
Adımlar:
100
Sınıflandırıcı Ücretsiz Rehberlik:
15.0
Örnekleme Algoritması:
Bazı Euler varyantı (Atalara ait, Ayrık)
Örnekleme algoritması, çıktıyı etkileyebilse de performansı büyük ölçüde etkiliyor gibi görünmemektedir. Otomatik 1111, en fazla seçeneği sunarken, Intel OpenVINO yapısı size herhangi bir seçenek sunmaz.
AMD RX 7000/6000 serisi, Nvidia RTX 40/30 serisi ve Intel Arc A serisi GPU’ları testimizin sonuçları burada. Her Nvidia GPU’nun iki sonucu olduğunu unutmayın; biri varsayılan hesaplama modelini (daha yavaş ve siyah) ve ikincisi Facebook’tan daha hızlı “xformers” kitaplığı (yeni sekmede açılır) (daha hızlı ve yeşil).
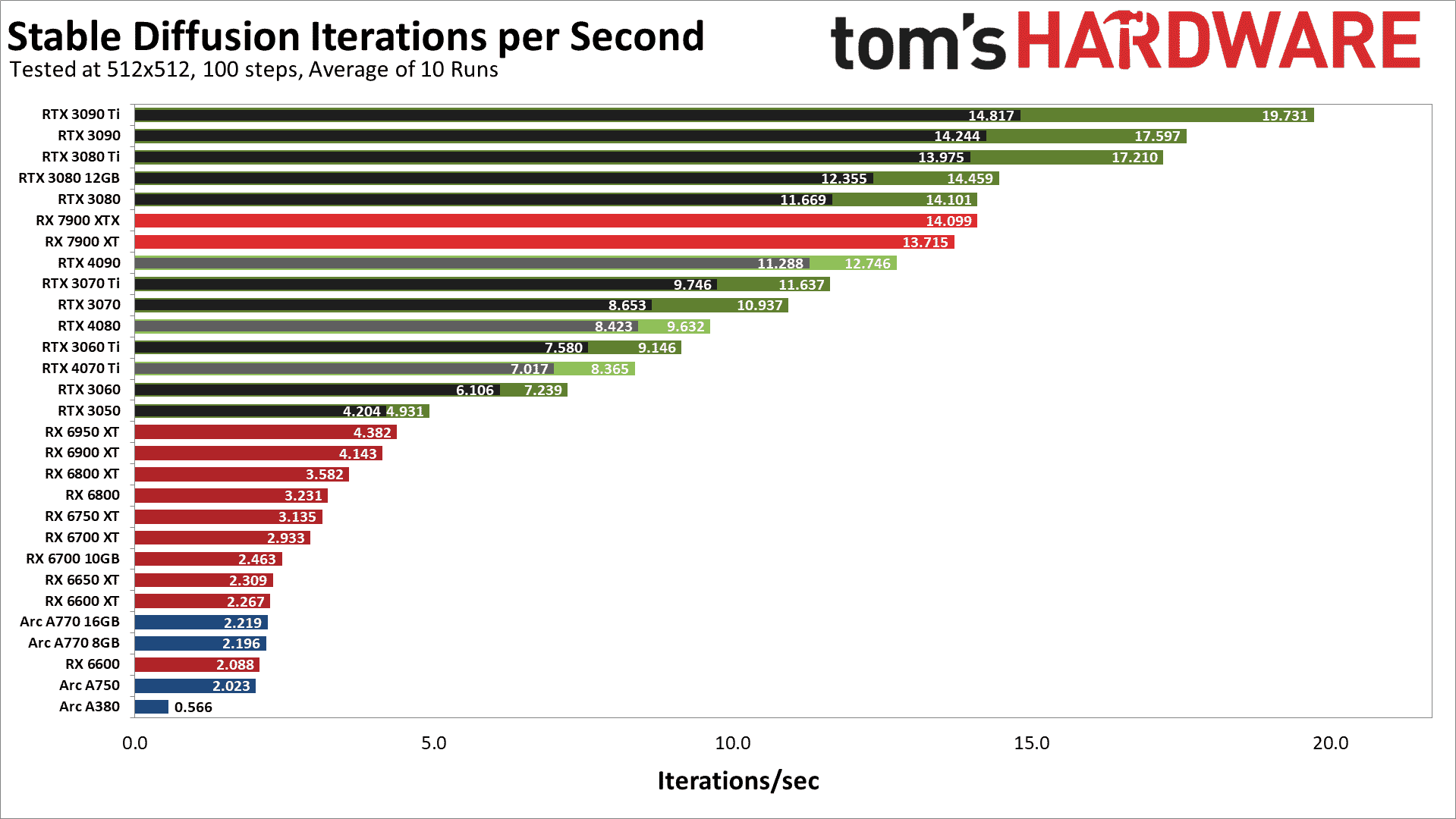
Beklendiği gibi, Nvidia’nın GPU’ları, AMD veya Intel’den daha üstün performans – bazen çok büyük marjlarla – sunar. Ancak, açıkça bazı anormallikler var. İlk testimizde en hızlı GPU, yapılandırılmış parametreleri kullanarak saniyede yaklaşık 20 yineleme veya görüntü başına yaklaşık beş saniye ile zirveye ulaşan RTX 3090 Ti’dir. İşler oradan düşüyor, ancak RTX 3080 bile temelde AMD’nin yeni RX 7900 XTX’ini bağlıyor ve RTX 3050, RX 6950 XT’yi geride bırakıyor. Ama tuhaflıklar hakkında konuşalım.
İlk olarak, RTX 4090’ın rekabeti alt üst etmesini bekliyorduk ve bu kesinlikle olmadı. Aslında, AMD’nin 7900 XT’sinden ve ayrıca RTX 3080’den daha yavaştır. Benzer şekilde, RTX 4080, 3070 ile 3060 Ti arasında yer alırken, RTX 4070 Ti, 3060 ile 3060 Ti arasında yer alır.
Uygun optimizasyonlar, RTX 40 serisi kartların performansını kolayca ikiye katlayabilir. Benzer şekilde, RX 7900 XT ile RX 6950 XT arasındaki önemli performans farkı göz önüne alındığında, optimizasyonları RDNA 2 GPU’ların performansını da ikiye katlayabilir. Bu, GPU kıyaslama hiyerarşimizde gördüklerimize dayanan bir tahmindir, ancak bu ilk sonuçlarda kesinlikle bir tuhaflık var.
Intel’in Arc GPU’ları, özellikle normal FP32 hesaplamaları olarak 4 kata kadar çıktı sağlaması gereken XMX (matris) işlemlerini destekledikleri için, şu anda çok hayal kırıklığı yaratan sonuçlar veriyor. Kullandığımız mevcut Kararlı Difüzyon OpenVINO projesinin de iyileştirme için çok yer bıraktığından şüpheleniyoruz. Bu arada, SD’yi bir Arc GPU’da denemek ve çalıştırmak istiyorsanız, ‘stable_diffusion_engine.py’ dosyasını düzenlemeniz ve “CPU”yu “GPU” olarak değiştirmeniz gerektiğini unutmayın — aksi takdirde hesaplamalar için grafik kartlarını kullanmaz ve önemli ölçüde daha uzun sürer.
Sonuçlara geri dön. Belirtilen sürümler kullanıldığında, Nvidia’nın RTX 30 serisi kartları harika, AMD’nin RX 7000 serisi kartları harika, RTX 40 serisi düşük performans gösteriyor, RX 6000 serisi gerçekten düşük performans gösteriyor ve Arc GPU’ları genel olarak zayıf görünüyor. Güncellenen yazılımla işler kökten değişebilir ve yapay zekanın popülaritesi göz önüne alındığında, daha iyi ayarlama görmemizin (veya daha iyi performans sunmak için zaten ayarlanmış doğru projeyi bulmamızın) yalnızca an meselesi olduğunu düşünüyoruz.
Yine, bu projelerin herhangi birinin tam olarak ne kadar optimize edildiği net değil, ancak çeşitli GPU’lardan maksimum teorik performansa (TFLOPS) bakmak ilginç olabilir. Aşağıdaki tablo, uygulanabilir olduğunda tensör/matris çekirdekleri kullanılarak her bir GPU için teorik FP16 performansını göstermektedir.

Nvidia’daki bu Tensör çekirdekleri, en azından teoride açıkça bir yumruk atıyor, ancak Açıkçası, Kararlı Yayılma testimiz bu rakamlarla tam olarak uyuşmuyor. Örneğin, kağıt üzerinde RTX 4090 (FP16 kullanarak), RTX 3090 Ti’den %106’ya kadar daha hızlıyken, testlerimizde %35 daha yavaştı. Ayrıca, kullandığımız Stable Difüzyon projesinin (Otomatik 1111), Ada Lovelace GPU’lardaki yeni FP8 talimatlarından yararlanmaya çalışmadığını ve bunun da potansiyel olarak RTX 40 serisinde performansı ikiye katlayabileceğini varsayıyoruz.
Bu arada, Arc GPU’lara bakın. Matris çekirdekleri, RX 6800 civarında A380 ile RTX 3060 Ti ve RX 7900 XTX’e benzer performans sağlamalıdır. Pratikte, Arc GPU’lar bu işaretlerin yakınından bile geçemez. En hızlı A770 GPU’lar, RX 6600 ve RX 6600 XT arasına yerleşir, A750, RX 6600’ün hemen gerisinde kalır ve A380, A750’nin yaklaşık dörtte biri hızındadır. Yani hepsi beklenen performansın yaklaşık dörtte biri, ki bu XMX çekirdekleri kullanılmıyorsa anlamlı olur.
Yine de Arc’taki oranlar doğru görünüyor. A380’deki teorik bilgi işlem performansı, A750’nin yaklaşık dörtte biri kadardır. Büyük olasılıkla, hesaplamalar için tam hassasiyetli FP32 modunda gölgelendiriciler kullanıyorlar ve bazı ek optimizasyonları kaçırıyorlar.
Dikkat edilmesi gereken diğer bir nokta da, AMD’nin RX 7900 XTX/XT’sindeki teorik bilgi işlemin, RX 6000 serisine kıyasla çok gelişmiş olması ve bellek bant genişliğinin kritik bir faktör olmamasıdır — 3080 10GB ve 12GB modelleri nispeten birbirine yakındır. Bu nedenle, 7900 XTX, 6950 XT’ye kıyasla neredeyse üç kat ham bilgi işlem yaptığından, belki de yukarıdaki AMD sonuçları tamamen söz konusu değildir. 7900 XT’nin neredeyse XTX kadar iyi performans göstermesi dışında, burada ham bilgi işlem ölçtüğümüz %3 yerine yaklaşık %19 oranında XTX’i tercih etmelidir.
Sonuç olarak bu, gerçek bir performans beyanından ziyade AMD, Intel ve Nvidia GPU’lardaki Stable Difusion performansının zamanındaki bir anlık görüntüsüdür. Tam optimizasyonlarla performans, teorik TFLOPS tablosuna daha çok benzemeli ve kesinlikle daha yeni RTX 40 serisi kartlar, mevcut RTX 30 serisi parçaların gerisinde kalmamalıdır.
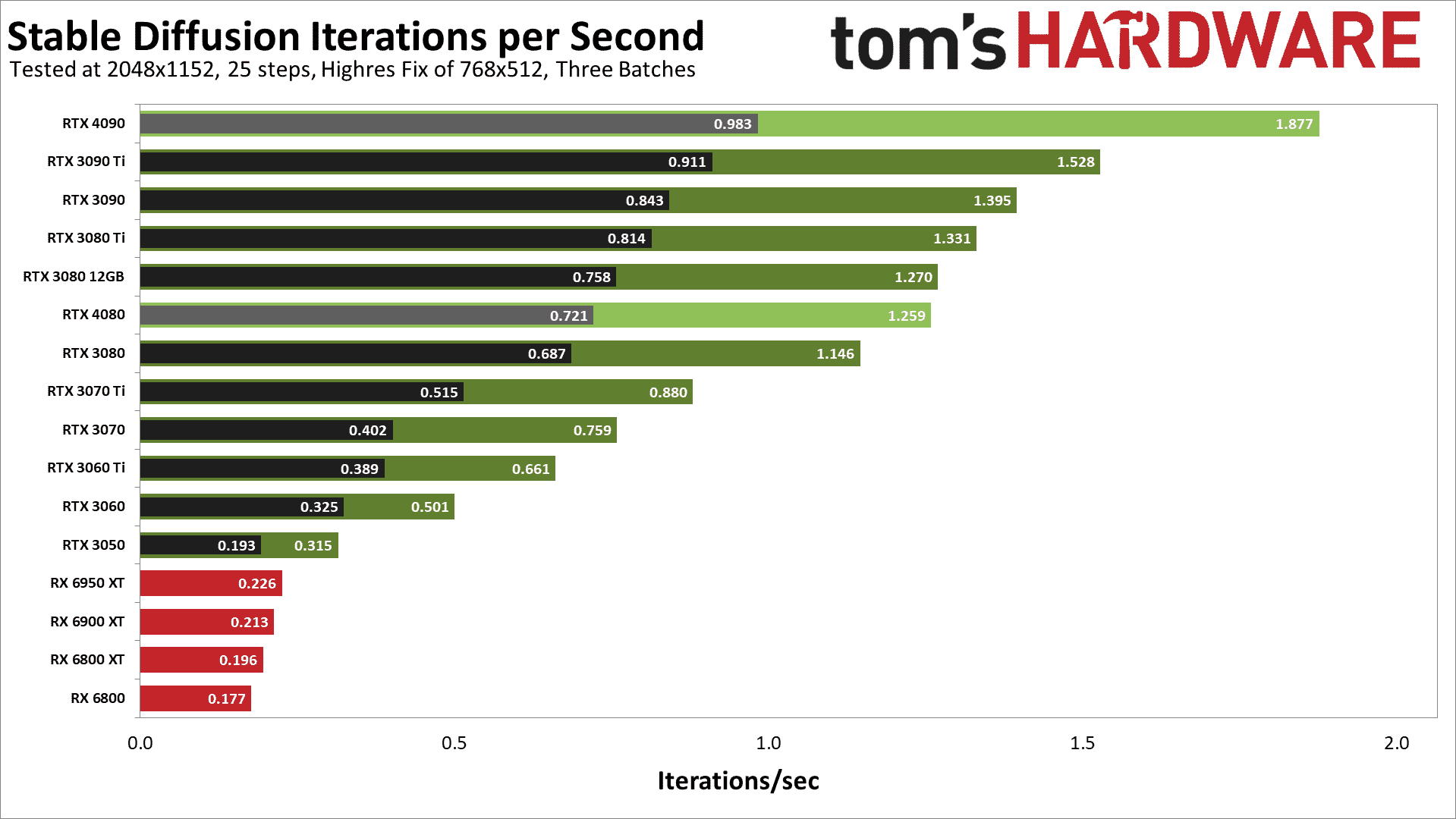
Bu da bizi daha yüksek çözünürlüklü testler yaptığımız son bir grafiğe getiriyor. Henüz tüm yeni GPU’ları test etmedik ve test ettiğimiz AMD RX 6000 serisi kartlarda Linux kullandık. Ancak 2048×1152’lik daha karmaşık hedef çözünürlüğü, en azından RTX 4090’dan daha iyi yararlanmaya başlamış gibi görünüyor. Önümüzdeki yıl bu konuyu daha fazla tekrar ele alacağız.