

AMD, G/Ç kalıbının (IOD) üzerine yığılmış bir makine öğrenimi (ML) hızlandırıcısı içeren bir işlemcinin patentini aldı. Patent, AMD’nin entegre FPGA veya GPU tabanlı makine öğrenimi hızlandırıcılarıyla özel amaçlı veya çipler üzerinde veri merkezi sistemi (SoC’ler) oluşturmayı planladığını gösteriyor.
AMD’nin artık CPU’larına önbellek ekleyebildiği gibi, işlemci G/Ç kalıbının üstüne bir FPGA veya GPU ekleyebilir. Ancak daha da önemlisi, teknoloji şirketin gelecekteki CPU SoC’lerine başka tür hızlandırıcılar eklemesine izin veriyor. Herhangi bir patentli çalışmada olduğu gibi, patent, teknolojiye sahip tasarımların piyasaya çıktığını göreceğimizi garanti etmez. Bununla birlikte, bize şirketin Ar-Ge’sinde hangi yönde ilerlediğine dair bir fikir veriyor ve bu teknolojiye dayalı ürünlerin veya yakın bir türevinin piyasaya çıktığını görme şansımız var.
AI/ML Hızlandırıcısını bir I/O Kalıbının Üzerine Yığınlama
AMD’nin patenti ‘Doğrudan bağlantılı makine öğrenimi hızlandırıcısı’ AMD’nin yığınlama teknolojilerini kullanarak bir IOD ile CPU’larına nasıl bir ML hızlandırıcı ekleyebileceğini açıkça anlatıyor. Görünüşe göre AMD’nin teknolojisi, özel bir hızlandırıcı bağlantı noktasına sahip bir G/Ç kalıbının üzerine makine öğrenimi iş yükleri için bir alan programlanabilir işleme dizisi (FPGA) veya bir hesaplama GPU’su eklemesine izin veriyor.
AMD, bir hızlandırıcı eklemenin birkaç yolunu açıklar: biri kendi yerel belleğine sahip bir hızlandırıcı içerir, diğeri bu tür bir hızlandırıcının bir IOD’ye bağlı belleği kullandığı anlamına gelirken, üçüncü senaryoda, bir hızlandırıcı muhtemelen sistem belleğini kullanabilir ve bunda durumda, bir IOD’nin üstüne istiflenmesi bile gerekmez.
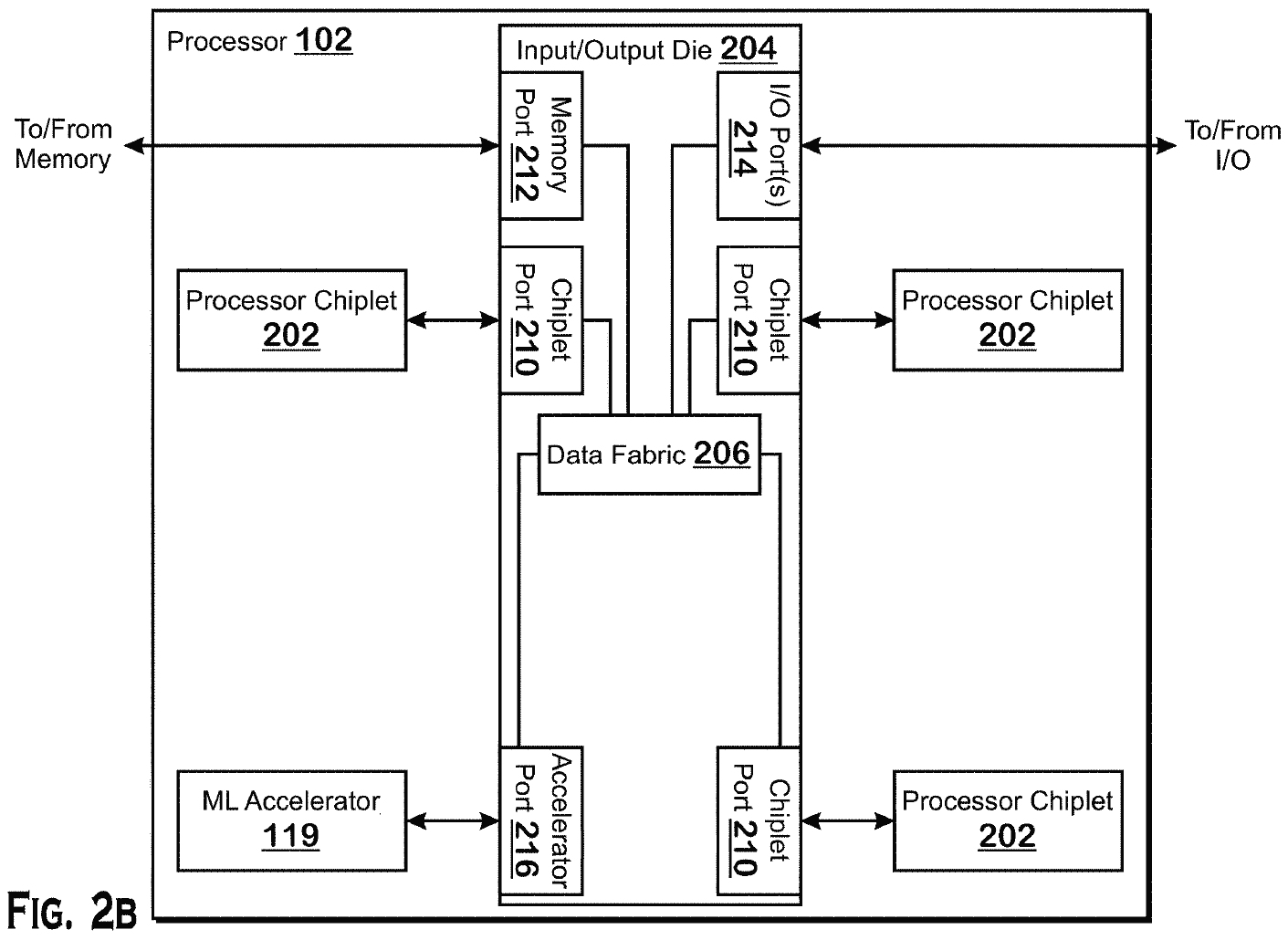
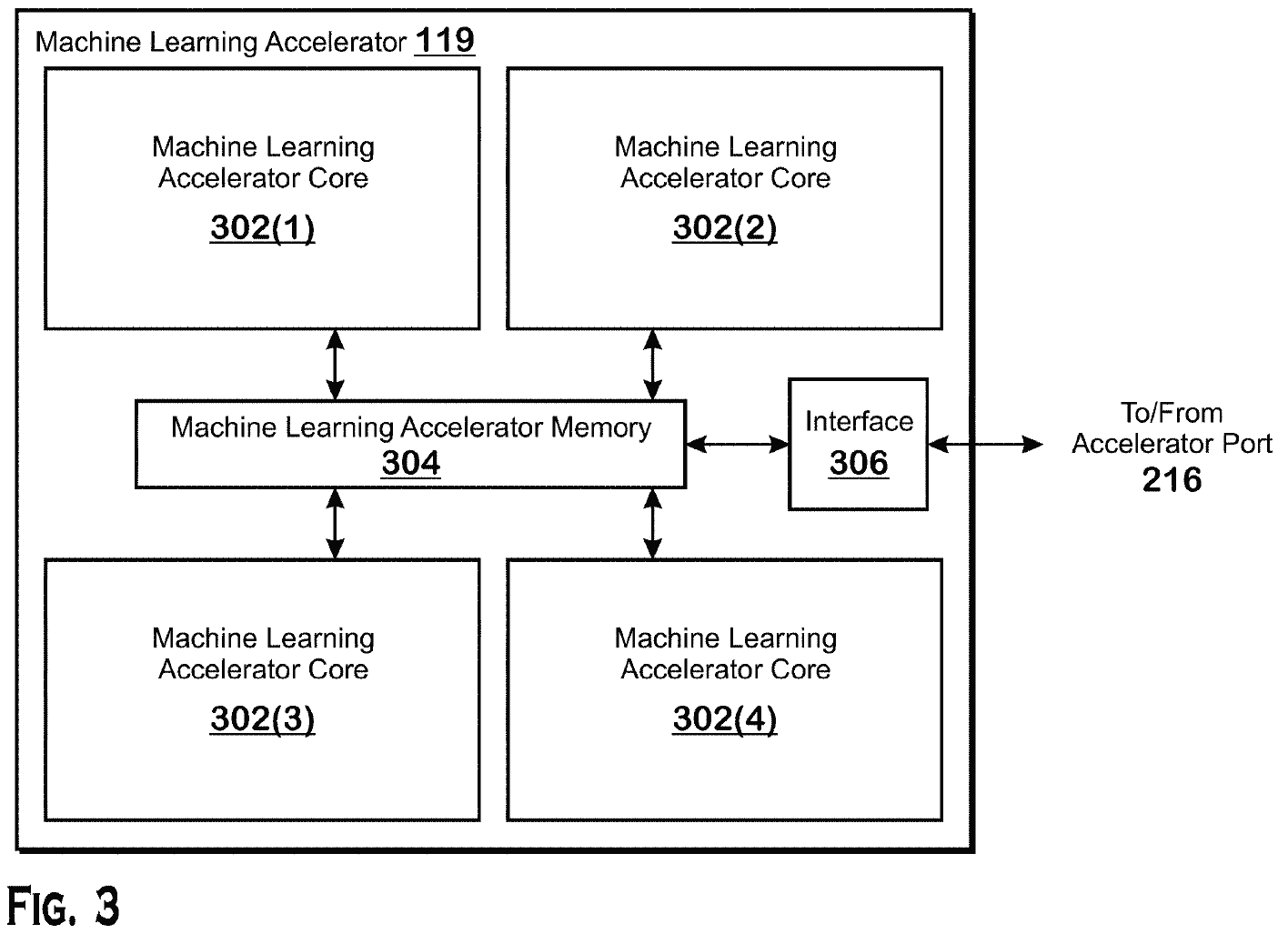
Makine öğrenimi teknikleri, gelecekteki veri merkezleri tarafından yaygın olarak kullanılacaktır. Ancak, daha rekabetçi olabilmek için AMD’nin çiplerini kullanarak makine öğrenimi iş yüklerini hızlandırması gerekiyor. Bir CPU G/Ç kalıbının üzerine bir makine öğrenimi hızlandırıcısı yerleştirmek, pahalı özel makine öğrenimi için optimize edilmiş silikonu CPU yonga setlerine entegre etmeden makine öğrenimi iş yüklerini önemli ölçüde hızlandırmasına olanak tanır. Ayrıca yoğunluk, güç ve veri çıkışı avantajları sağlar.
Patent, AMD ve Xilinx’in yönetim ekiplerinin AMD’nin Xilinx’i satın alacağı konusunda kesin bir anlaşmaya vardıklarını açıklamasından bir aydan biraz daha uzun bir süre önce, 25 Eylül 2020’de dosyalandı. Patent, 31 Mart 2022’de yayınlandı ve AMD üyesi Maxim V. Kazakov mucit olarak listelendi. AMD’nin Xilinx IP’li ilk ürünlerinin 2023’te çıkması bekleniyor.
AMD’nin patentini gerçek ürünler için kullanıp kullanmayacağını bilmiyoruz, ancak hemen hemen her CPU’ya ML yetenekleri eklemenin zarafeti, fikri makul kılıyor. AMD’nin kod adlı EPYC ‘Genoa’ ve ‘Bergamo’ işlemcilerinin bir hızlandırıcı bağlantı noktasına sahip bir G/Ç kalıbı kullandığını varsayarsak, ML hızlandırıcılı Genoa-AI ve Bergamo-AI CPU’lar olabilir.
AMD’nin, mevcut nesil EPYC 7003 serisinin cTDP’sinden iki kat daha yüksek olan 5. Nesil EPYC ‘Turin’ işlemcileri için 600W yapılandırılabilir termal tasarım gücüne (cTDP) baktığı söylentisi de dikkate değer. ‘Milan’ işlemciler. Ayrıca, AMD’nin 4. Nesil ve 5. Nesil EPYC CPU’ları için AMD’nin SP5 platformu, işlemcilere çok kısa süreler için 700W’a kadar güç sağlar.
AMD’nin gelecekteki 96 – 128 (Genoa ve Bergamo) CPU’larının ne kadar güce ihtiyaç duyacağını bilmiyoruz, ancak işlemci paketine bir ML hızlandırıcı eklemek tüketimi kesinlikle artıracaktır. Bu amaçla, yeni nesil sunucu platformlarının gerçekten de yığın hızlandırıcılara sahip CPU’ları destekleyebileceğinden emin olmak çok mantıklı.
Nihai Veri Merkezi SoC’leri Oluşturma
AMD, 2006’da ATI Technologies’i satın aldığından beri veri merkezi hızlandırılmış işlem birimleri (APU’lar) hakkında konuşuyor. Son 15 yılda, tipik iş yükleri için genel amaçlı x86 çekirdeklerini ve yüksek düzeyde paralellik için Radeon GPU’ları entegre eden çok sayıda veri merkezi APU projesini duyduk. iş yükleri.
Bu projelerin hiçbiri hayata geçmedi ve bunun birçok nedeni var. Bir dereceye kadar, AMD’nin Buldozer çekirdekleri rekabetçi olmadığı için, çok sınırlı talep görebilecek büyük ve pahalı bir çip inşa etmek pek mantıklı gelmedi. Diğer bir neden ise, geleneksel Radeon GPU’ların veri merkezi/AI/ML/HPC iş yükleri için gereken tüm veri biçimlerini ve talimatları desteklememesi ve AMD’nin ilk bilgi işlem merkezli CDNA tabanlı GPU’sunun ancak 2020’de ortaya çıkmasıdır.
Ama artık AMD’nin rekabetçi bir x86 mikromimarisine, bilgi işlem odaklı bir GPU mimarisine, Xilinx’ten bir FPGA portföyüne ve Pensando’dan bir programlanabilir işlemci ailesine sahip olduğu için, bu çeşitli IP bloklarını tek bir büyük çipe koymak pek mantıklı olmayabilir. . Tam tersine, TSMC ve AMD’nin kendi Infinity Fabric ara bağlantı teknolojisi tarafından sunulan günümüzün paketleme teknolojileri ile, genel amaçlı x86 işlemci yongaları, bir G/Ç kalıbı içeren çok döşemeli (veya çok yongalı) modüller oluşturmak çok daha mantıklı. GPU veya FPGA tabanlı hızlandırıcıların yanı sıra.
Aslında, yerleşik çeşitli IP’ye sahip büyük bir monolitik CPU yerine çok yongalı bir veri merkezi işlemcisi oluşturmak daha mantıklı. Örneğin, çok döşemeli bir veri merkezi APU’su, TSMC’nin performans açısından optimize edilmiş N4X düğümü kullanılarak yapılan bir CPU döşemesinden ve ayrıca yoğunluğu optimize edilmiş bir N3E işlem teknolojisi kullanılarak üretilen bir GPU veya FPGA hızlandırıcı döşemesinden yararlanabilir.
Evrensel Hızlandırıcı Bağlantı Noktası
Patentin bir diğer önemli kısmı, bir FPGA veya bir hesaplama GPU’su kullanarak makine öğrenimi iş yüklerini hızlandırmak için tasarlanmış özel bir uygulama değil, herhangi bir CPU’ya özel amaçlı bir hızlandırıcı ekleme ilkesidir. Hızlandırıcı bağlantı noktası, AMD’nin G/Ç kalıplarında sunulan evrensel bir arabirim olacaktır, dolayısıyla AMD, işlemcilerine istemci veya veri merkezi uygulamalarına yönelik başka türlerde hızlandırıcılar ekleyebilir.
Patentin bir açıklaması, “Buradaki açıklamaya dayanarak birçok varyasyonun mümkün olduğu anlaşılmalıdır”. “Uygun işlemciler, örneğin, genel amaçlı bir işlemciyi, özel amaçlı bir işlemciyi, geleneksel bir işlemciyi, bir grafik işlemcisini, bir makine öğrenme işlemcisini, [a DSP, an ASIC, an FPGA]ve diğer tümleşik devre (IC) türleri. […] Bu tür işlemciler, işlenmiş donanım tanımlama dili (HDL) talimatlarının ve ağ listeleri (bilgisayar tarafından okunabilir bir ortamda saklanabilen bu tür talimatlar) dahil olmak üzere diğer aracı verilerin sonuçları kullanılarak bir üretim süreci yapılandırılarak üretilebilir.
FPGA’lar, GPU’lar ve DSP’ler bugün bile çeşitli uygulamalar için kullanılabilirken, veri merkezleri için veri işleme birimleri (DPU’lar) gibi şeyler ancak önümüzdeki yıllarda önem kazanacaktır. DPU’lar esasen AMD’nin şimdi sahip olduğu gelişmekte olan bir uygulamadır. Ancak veri merkezi daha fazla veri türünü ve daha hızlı işlemek için dönüştükçe (ve Apple’ın ProRes RAW gibi uygulamaya özel hızlandırmayı istemci SoC’lerine entegre etmesi gibi istemci PC’ler de öyle), hızlandırıcılar daha yaygın hale geliyor. Bu, onları herhangi bir veya hemen hemen her sunucu işlemcisine eklemenin bir yolu olması gerektiği anlamına gelir. Gerçekten de, AMD’nin hızlandırıcı bağlantı noktası, bunu yapmanın nispeten basit bir yoludur.